关键词:Orcle SCADA 数据利用率
0 引言
随着衡水电网调度自动化水平的不断提高,遥测、遥信数据的准确性也不断提高,电网运行的大量数据不仅成为科学调度的依据,在辅助公司决策方面也发挥着越来越重要的作用。比如:方式人员在安排电网运行方式时,需要每月各站有功、电压等大量统计信息;计划部门需要历年的电网运行数据作为制定计划的依据;用电处需要市区电网的遥测信息作为开展工作的参考。总之,企业各部门对数据的需求量不断增长。
1 衡水电网调度自动化系统数据利用现状
1.1 衡水电网数据利用率
衡水电网调度自动化系统所存储的数据有两类:遥测值和计算量。系统每天存储的数据不仅包括288个整5分钟的实时值,还包括每天的统计值,(如:最大值、最小值及相应的时间等14个属性)。目前系统中共有计算量685个,遥测量2430个。实时数据报表占128张,统计数据报表占19张,每张报表的平均容量为576个数据点,在以上分析的基础上我们计算出了目前的数据利用率。

(系统每天存储实时数据总数=288×(2430+685)=897120个,可用数据总数=576×128=73728个
系统每天存储统计数据总数=14×(2430+685)=43610个, 可用数据总数=576×19=10944个)
从上表中我们可以看到,衡水电网调度自动化系统中所存储数据的利用率只有约9%,大量的电网运行数据不能被直接访问。
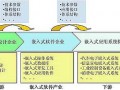
1.2 衡水电网调度自动化系统数据访问流程

图1 SCADA系统数据访问流程
系统设计时采用了非标准数据库,对系统数据的访问只能使用PGC2000系统提供的功能来完成,从而限制了对数据的访问。
2 解决对策
通过上面的分析可以得出,系统功能的限制和系统未采用标准数据库是导致数据利用率低的主要原因。
对于系统功能的限制,在单一的SCADA系统中,数据库的建立和管理都采用文件方式,调度员的操作只是调用画面,由系统维护人员来完成数据的插入、修改等操作,如果通过增加画面的数量来提高数据利用率,势必以牺牲系统的响应时间和稳定性为代价,这是不可取的。
对于系统未采用标准数据库,由于系统未采用标准的数据库,导致了利用数据方法繁琐,数据访问方式不合理,利用数据方法繁琐导致用户不能在期望的时间内访问到所需要的数据,数据访问方式不合理导致主机负载过高,不能在有效响应用户的数据请求,这些都限制了用户对系统数据的访问,导致了数据可用率低的现状。
我们决定在不对现有软件进行改动的前提下,通过将非标准数据库转换成标准数据库的方法来提高数据的利用率。
为此,我们制定了如下解决方案:
a.选择合适的网络结构;
b.安装Oracle数据库管理软件,建立数据库表结构;
c.理清SCADA系统数据的存放格式,编写数据转换模块;
d.利用标准数据库查询语言进行数据查询。
3 实施步骤
3.1 网络结构的选择
为减轻实时服务器的负担,将原有的两台COMPAQ DS-10小型机作为历史服务器,分别安装Oracle 数据库,采用C/S结构,标准数据库存放在历史服务器上,同时在工作站上安装Oracle客户端,用户通过网络从工作站上访问数据库。
3.2 建立表结构
衡水电网SCADA系统中,数据的存储是以天为单位,每天生成一个数据文件,少数计算量以年为单位,每年生成一个文件,每天零点进行统计后对该文件进行更新,增加记录。
由于数据量大,也为了与习惯一致,在设计ORACLE数据库时要建立一个包含站名、站号、点名、点号等的数据字典文件,同时将每年的遥测数据建立一个历史数据表文件,将每年遥测数据的统计值建立一个统计数据表文件。
a. 创建一个包含站名、站号、点名、点号的数据字典文件
CREATE TABLE DBDICTIONARY (
SERIAL int NOT NULL ,
STNNO int NOT NULL , 来源:输配电设备网
PNTNO int NOT NULL ,
PNTTYPE char (1) NOT NULL ,
STNNAME varchar2 (40) NOT NULL ,
PNTNAME varchar2 (40) NOT NULL ,
DTCREATE date NULL ,
PRIMARY KEY("SERIAL"),
UNIQUE("SERIAL")
)
PARTITION BY RANGE(STNNO)
(…)
…
b. 创建包括日最大(小)值、最大(小)值时刻、平均值等的年度统计值表
CREATE TABLE DBSTATISTICS2005 (
SERIAL int NOT NULL ,
DTDATE date NOT NULL ,
NUM_VALID int NOT NULL ,
NUM_NORMAL int NOT NULL ,
MAXIMUM real NOT NULL ,
DTMAXIMUM date NOT NULL ,
…
)
PARTITION BY RANGE(DTDATE)
(…)
…
c. 创建包括所有遥测点、计算量点的全天288个点的年度实时值表
CREATE TABLE DBHISTORY2005 (
SERIAL int not null,
DTDATE date not null,
D1 real, D2 real,…)
PARTITION BY RANGE(DTDATE)
(…)
…
3.3 编写数据转换模块
由于在数据存储中厂家采用了非标准的数据库,我们不清楚数据的存储形式,因此与厂家协作编写数据转据转换模块,在设计数据转换模块时我们考虑了下面几个问题:
a. 数据转换模块应不依赖于调度自动化主程序,应具有良好的可移植性;
b. 由于采用双机冗余的网络结构,数据转换模块应具有灵活选择数据源和目的数据库的功能。
c. 数据转换模块可以自动运行,也可手动运行,以保证在修改了实时数据库后能及时对历史数据库做出相应的修改。
d. 为满足数据查询灵活性的要求,数据转换模块应具备灵活选择转换时间段的功能。
4 实施效果
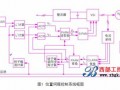
4.1 经过反复修改,数据转换程序主界面如下图所示: 来源:输配电设备网

图2 数据转换程序主界面
利用这个数据转换模块可以方便的将SCADA系统生成的非标准数据库文件转换成标准Oracle数据库文件。
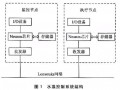
4.2 转换后数据访问流程如图3所示。

图3 数据访问流程图
这种数据访问形式的优点在于:
a. 利于用标准数据库查询语言对数据进行查询
b. 利于实现网络负载平衡;
c. 提高整个电网调度自动化系统的容错性;
d. 提高数据存储的安全性。
4.3 应用
例如查询PID为 "02A011" 在2005年的最大值,可使用下列语句:
select max(maximum)
from dbdictionary, dbstatistics2005
where dbdictionary.serial = dbstatistics2005.serial
and dbdictionary.stnno = 02
and dbdictionary.pnttype = A
and dbdictionary.pntno = 11
5 结束语
通过将电网运行数据转换到ORACLE标准数据库中的方式,可以用标准数据库查询语言实现对任意点的数据查询,SCADA采集的数据能更好的被企业各部门所共享,数据的利用率大大提高。