关键词:主控系统;核心路由器;容错;热备份;硬件冗余
Router Muster Control System
Wang Xin-min
Abstract: With the hardware redundancy and software fault-tolerant unifies, hot backup and the duplex working ways which replaced the traditional the fault-tolerant hot backup ways, proposed one kind of fault-tolerant design proposal suitable for the core router muster control system. Analyzed the basic question of muster control system in the fault-tolerant design, and aimed at these questions to propose this fault-tolerant system concrete realization plan. The test result indicated that, used this design proposal ,the muster control software system has good fault-tolerant performance and the breakdown restores ability, could satisfy the high usability request of the muster control software system in core router.
Keyword: muster control ;core router; fault tolerant; hot backup; hardware redundancy
1 前言
随着高速网络的迅速发展以及人们对网络的依赖性越来越来高,主干网络的可靠性显得尤为重要。并且随着国家对网络基础建设的投入不断加大力度,以及对网络核心设备国产化的坚定决心,促使了网络核心设备的研发在国内获得了迅速发展,并取得了一定的研究成果。但与国外一些知名厂商和研究机构设计的设备还是有一定差距,这种差距不仅仅是在功能上,更多的是体现在诸如可靠性、容错性、扩展性等等这些方面,而这些方面恰恰能影响到该设备所能提供的服务质量。因此本文针对网络核心设备——核心路由器上主控系统高容错性设计做了一定研究与探讨,并提出了一种适于核心路由器主控系统的高容错性实现方案。
2 高可靠性技术
高可靠性是指可持续的、具有一致性和完整性的数据访问。高可用性系统通过提高服务器可靠性、磁盘可靠性、应用程序可靠性来达到高可用性的要求。具体实现可以通过共享磁盘阵列来提高磁盘可靠性,使用冗余网络来提高网络可靠性,使用合作的服务器来提高服务器的可靠性,通过应用程序的探测与有效恢复来提高应用程序的可靠性。
路由器作为计算机网络的核心设备,其高可用性至关重要。对于路由器来说要实现高可用性,从硬件来看,要有一个很好的体系结构,各种冗余非常完善。关键部件如路由引擎和交换矩阵要有冗余。从软件来看,其自身要强壮,另外在遇到更换硬件、系统升级、增加板卡和改变链路等网络调整时,软件要有能力保证整个网络业务不受局部调整的影响,让整个网络体现出非常高的可用性,它要保证路由引擎进行不丢包的切换。主引擎发生故障,切换到副引擎时不丢包,平滑切换,否则硬件的冗余就没有意义,是假冗余。另外还要保证平稳重启。通常当路由重启时,由此产生的路由重新计算和网络范围的路由更新会消耗掉处理资源,并有可能出现黑洞或瞬时转发循环形式的非预期网络行为。而平稳重启会避免这种情况的发生。
对于网络设备可用性的研究,目前主要集中在设备生产厂家进行,技术专用性和保密性强,可参考的设计细节不多。不过对于可维修的系统,衡量其可靠性的指标叫做可用度,相应的理论又叫做可用性理论。核心路由器就是一个可维修的系统。根据系统的可靠度,从高到低可以分为四个档次:连续可用性系统(Continuous Availability System),容错系统(Fault Tolerance Syetem),高可用系统(High Availability System),容灾系统(Disaster Tolerance System)。前两种一般用于航天和军工等领域,对于核心路由器,要求达到高可用系统。系统可用性是指在容许的极限故障数目内,系统按规范成功运行的概率。
可用性理论的研究主要包括两个范畴:提高元部件可靠性达到系统可靠的避错技术和使用给定器件构成高可靠性系统的容错技术。目前元部件的可靠性研究已十分成熟,并在工业中广泛采用。而且对于一个系统,无论采用多少避错设计方法,总不能保证永远不出错。所以容错技术成为了提高系统可用性的研究热点。目前,核心路由器的可靠性实现就普遍采用了这种技术。
3 核心路由器的主控系统容错系统设计
3.1主控系统容错系统设计中的基本问题
基于容错需求的考虑,当主控系统出现软硬件故障时路由器仍要正常工作,故硬件配置方面采用1+1冗余设计,配备主用(Active)和备用(Standby)两块主控板,构建双主控热备容错系统。当主用主控板发生故障,系统自动进行主备切换,由备用主控板接替主用板工作,保证业务的正常运行。当主用模块发生严重故障或主用复位时,将触发自动倒换方式,及时倒换到备用板。这种1+1冗余设计可扩展到N+1冗余设计。
整个切换过程要保证对用户是透明的,需要考虑的重点和实现的难点在于主备系统间数据库一致性问题、平滑切换技术的实现和故障监测机制。
l 数据库一致性问题
路由器主控板上有系统实时运行记录的数据,因此正常工作过程中需要进行实时的系统数据备份,以保证做到主用和备用上的数据库一致,否则在主备切换时,备用就不能正常接替主用。针对该问题,在高可用性模块的设计中,采用了一种双工与热备相结合的不完全热备设计,需要备份的数据主要是系统数据库中的路由表项和转发表表项。
所谓双工与热备相结合的不完全设计是指,双主控板上都运行心跳探测程序用于故障探测,主用主控板上运行路由器正常工作所需要的所有应用程序,而备用主控板上运行部分重要应用程序,这些程序正常工作,和主用上的这些程序有相同的输入数据,但处理结果并不输出。这样的设计保证了路由器出现故障进行切换时低耗时,减轻了需要备份的数据量,既又不象完全双工工作方式那样浪费资源,又避免了热备工作方式的很多不足,性能明显优于纯粹的热备或者双工方式。
数据备份有冷备份和热备份两种:冷备份是在数据库已经正常关闭的情况下,进行完整数据库的备份,是最快和最安全的方法,但是冷备份的最大问题是必须在数据库关闭的情况下进行,当数据库处于打开状态时,执行数据库文件系统备份是无效的。
热备份是在数据库运行的情况下,采用archivelog mode方式备份数据。有双机镜像和共享磁盘阵列两种方案,双机镜像方案可选择将主数据库服务器上的表、文件、数据库或全部内容通过专用连接通道镜像到备用服务器上作,优点是简单、便宜,缺点是降低系统资源。共享磁盘阵列方案为两台主机共用一个磁盘阵列,优点是不降低系统性能,为目前较为流行的主流技术,但要求磁盘阵列具有较高的可靠性。
对于运行在骨干网中的路由器,冷备份显然不适用,因为路由器运行过程中不可能定时关闭数据库来备份数据,更不可能在路由器出现故障时再备份数据,因此采用热备份。鉴于要备份的数据量不大,不必要采取双机镜像和共享磁盘阵列方式,在本设计中采用了一种新型的数据热备份方式:将需要备份的数据以日志文件的形式存储,通过TCP传输的方法将文件转化为数据流由主用备份到备用上,实现实时备份。面向连接的TCP传输可靠且速度快,丢失文件的概率极小,故非常可靠。
l 平滑过渡――切换延时问题
路由器主控系统出现故障时,要能够对用户透明地进行主备切换,就要实现系统间的无缝切换,减少切换过程中的时延并降低数据丢失率。无缝切换是一种完美的切换,包括快速切换和平滑切换两个方面。快速切换意味着低延迟,平滑切换就是低的数据包丢失率,无缝切换是两者的结合,即低延迟和低丢失率。对于快速切换,要求在单板掉链之前完成切换过程,使备用接替主用的工作,保证路由器中的各个流程正常不受主控故障的影响,不影响网络的正常运行;对于平滑切换,有两点要求,一是切换时,主备用主控板上的数据库是一致的,二是在主备用数据库一致的基础上,备用启用后能在规定的时间[4]内完成备份数据的导入。所谓规定的时间,也包括在切换的总时间内,切换时间[4]=发现故障的时间+启用切换的时间+故障接管时间。
l 故障监测机制
系统中的两块主控板,经过主备协商后确定主备地位,一块为Master状态,控制整个系统;另一块为Slave状态,处于备份状态。两块主控板之间通过UDP传输心跳报文交互自身的状态数据来识别主控的软/硬件故障。路由器正常运行过程中,主用和备用主控板之间定时互相发送keepalive报文进行心跳探测,报文内容中包含了自身的状态信息。备用在定时器到期前未收到来自主用的keepalive报文就认为主用失效,进入主备切换成为新主用,自动接管原主用的服务程序,继续提供服务。原主用从故障中恢复或被更换后,会重新发送协商报文,与新主用取得联系,成为新备用,而不必再进行一次切换,节省了系统资源。
3.2高可用性模块的设计及实现
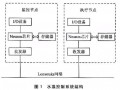
在主控软件容错系统的设计方案中,采用了两块主控板挂载八块单板,两块主控板之间通过面向无连接的UDP通信机制交互心跳数据,通过面向连接的TCP通信机制传输备份文件数据流;主控板与单板之间通过高速以太网连接。图1中给出了该系统的总体结构图。
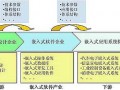
按照功能的不同,在设计方案中将高可用性模块划分为三个子模块:AS通信模块、AS系统监控模块和AS Keepalive模块,如图2所示。
AS通信模块,负责主控系统上高可用性模块与系统数据维护模块(SYSDATA)和板间通信模块(BDCOM)间的通信,数据备份和TCP传输;
AS监控模块,负责主控软件各个系统进程的监控与维护、管理等核心功能,当某个软件占cpu使用百分比过大时,认为该主控软件运行不正常,根据该软件的运行规则和重要性选择恢复策略,重启该进程或者进入主备切换;
AS Keepalive模块,负责两块主控板之间的主备协商,确定主控板的主备地位;在路由器正常运行过程中,定时向对方主控板发送keepalive报文进行心跳探测;针对网络拥塞可能导致的丢包,以及cpu排队处理多线程时可能超时处理keepalive报文,造成的主用主控“假死”现象,采用了再协商(Re-negotiation)技术,在超时收不到对方主控板发送的keepalive报文时不直接认为对方主控板故障,而是进行一次退避,与对方发送协商报文进行再协商,再协商与初始化过程中的主备协商不完全相同。采用Re-negotiation技术与通常采用的单纯固定不变的心跳探测技术相比较,可以更好地提高系统心跳环境适应能力和稳定性,更好地保证了系统的高可用性。

图 1 主控软件容错系统总体结构图

图 2 高可用性模块详细设计图
4 系统容错性的测试
本文利用Adtech AX/4000路由器测试仪,在不同负载下,对HAL的效率及可靠性进行了测试,测试结果如图3所示。测试时的发包速率服从马尔可夫调制泊松过程(MMPP),图3-1和图3-2分别给出了随着不同故障情况下,路由器吞吐率和时延的测试结果。测试结果表明该主控系统的容错设计可用对路由器运行中出现的各种错误做出一定的处理,虽然其延时和吞吐率会受到一定影响。尤其在10%的故障情况下,系统的延时并不是特别大,将可能地降低了系统故障对用户的影响。当然在高故障情况下,系统的吞吐率下降的非常明显,因此在下一步设计中将重点研究产生这一现象的原因,并加以改善。

图3-1 延时性测试

图3-2 吞吐率测试
5 总结
本文研究了T比特核心路由器的主控系统结构,设计了高可用性模块,该模块采用热备份模式,通过对主控板的硬件冗余设置,配合软件实现上的数据热备份、及心跳探测等技术消除T比特路由器中主控单点故障。该模块应用于T比特路由器主控软件系统中,当主用主控板发生故障时,可以快速、准确、平滑地进行主备切换,从而提高了系统的稳定性和可靠性,最终实现路由器的高可用性。
参考文献:
1 中华人民共和国信息产业部科学技术司,YD/T1097-2001《路由器设备技术规范—高端路由器》. 2001.
2 Cisco White Paper, The Evolution of High-End Router Architectures, Basic Scalability and Performance Considerations for Evaluating Large-Scale Router Designs
3 Vitesse Semiconductor Corporation, Longmont, Colorado, IQ2000 Network Processor Product Brief, 2000.
4 James Aweya,On the design of IP routers Part 1:Router architectures, Journal of Systems Architecture 46 (2000) pp:483-511.
颜永红, 张帆. TCAM路由更新的硬件优化[J]. 微计算机信息 , 2006,12-2:254-256。