本文以16-QAM RF发射数据泵的设计为例,介绍利用FPGA设计数字滤波器的技巧和器件选择方法,说明执行分布式计算时FPGA比DSP的优越之处。
所有数字逻辑的基本结构
16-QAM调制器
编码和码元映射
平方根升余弦滤波器
设计技巧
5 MHz载波
分布式计算(DA)技术
滤波器的实现
用现场可编程门阵列(FPGA)设计软件无线电和调制解调器可与DSP芯片媲美。虽然FPGA可轻而易举地实现卷积编码器等复杂逻辑功能,但在实现大量复杂计算方面却有很大的缺陷。即使用最快的FPGA来实现矩阵乘法器,其成本和性能也抵不上一个仅值5美元的DSP芯片。在用CAD工具设计时DSP仍是首选芯片,但是随着分布式计算(DA)技术的应用,FPGA再次受到设计师的喜爱。
FPGA的特性之一是结构灵活。事实上无线和调制解调数据通道的功能模块很容易映射到独立和并行的硬件节点上。采用一个只能分时运行的数字信号处理器时,调度多个时间要求紧迫的任务需要非常复杂的编程,而采用FPGA就避免了这一问题。
我们将在设计16-QAM射频发射数据泵的同时介绍FPGA特性,并详细描述如何方便地把数据通道功能模块转换为XILINX 4000系列FPGA的逻辑电路,从而准确地估计所需逻辑电路的数量。虽然满足相同系统需求及使用同一类型FPGA的16-QAM数据泵的设计曾在公开文献中发表过,但报道中的逻辑电路数量似乎比实际需要多得多。为了急于投放市场,产品很可能不用CAD工具进行设计。完全依赖CAD工具也未必总能得出最优的方案,还要付出大量辛勤的汗水、经验和创造性工作。
所有数字逻辑的基本结构
只要有足够的与非门及或非门等通用逻辑门即可构建任何数字逻辑。FPGA具有充足的逻辑门。Xilinx 4000系列的逻辑门采用真值表的形式,或者采用更为通用的16 字 x 1比特查找表(LUT)的形式,它可实现四个输入变量(查找表的地址线)的任意布尔函数功能。由于产生的函数功能通常相当于多个与非门的组合,所以LUT被视为基本的逻辑单元。Xilinx 4000系列可配置逻辑模块(CLB)包括两个16字的LUT,可组合产生五输入变量的任意布尔函数。此外LUT还可设置成两个16 x 1 RAM或一个32 x 1 RAM。
CLB成二维方阵排列,CLB及它们之间的互连可以分别配置。最小的XC4002包含一个8 x 8的CLB矩阵,最大的XC4085XL则包含一个48 x 48的CLB矩阵。每个LUT连接一个高达100 MHz的触发器。
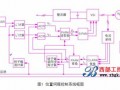
16-QAM调制器
16-QAM调制器包括RF发射数据泵的关键功能模块(见图1)。20-Mbps串行数据分为4比特码元组(SYMBOL)后,以每秒5兆码元的速率并行送至一个差分编码器和码元映射器(symbol mapper)。该映射器产生3比特的正交分量对。然后这些分量对由一对平方根升余弦滤波器进行脉冲整形,经过插值达到每秒20兆码元,再由5MHZ载波进行调制,将各输出相加后进行数模转换。设计的关键是采用一对插值脉冲整形滤波器。

为了有效地实现这种设计方法,有必要在确定逻辑门的总数时,将编码和映射功能模块以及一个5MHz调制器也考虑进去。
编码和码元映射
在确定编码器和信号映射器的逻辑数目时,我们可以借鉴过去标准调制解调器的设计。如V.32中的编码器包括一个提供180度双相保护的差分编码器和一个能加入冗余以减小接收器的位误差率(BER)的卷积编码器。编码器和映射器都是有限状态机实现的,所有状态由五个寄存器(2.5个 CLB)实现,连接逻辑由八个二输入异或门(4个CLB)及三个二输入与门(1.5 CLB)构成。在这个16-QAM发送器中,一个串并转换寄存器(2个CLB)捕获到四个20-Mbps的串行比特后形成一个4比特码元,这样编码器就可以处理降低到每秒5兆码元的数据流,而这种速率CLB很容易处理。数据通道控制需要沿着数据通道的寄存器进行时钟控制,所需CLB的数量少于15个。接着,一个经编码的5比特输出码元对应映射器的地址线,很简单,该映射器是一对3比特输出的LUT。
这些输出作为正交分量(I和Q) 映射一个二维平面(星座)内的码元位置。64个交叉点(星)中仅有16个代表有效的码元位置。映射器的大小为32字 x 3比特 x 2 即6个CLB。这些功能模块的CLB总数是31个。
平方根升余弦滤波器
平方根升余弦滤波器是在传输通道的有限带宽内抑制码元相互干扰的一种可行方法。频谱由发射器和接收器单元分别调制,形成了平方根升余弦滤波器。滤波器形状及其系数用QEDesign 1000软件辅助开发。图2为12比特定点计算的32抽头有限脉冲响应(FIR)滤波器的响应图。我们将采用一个12比特滤波器模型并确定其逻辑门数(采用12比特量化的方式,QEDesign程序仅需28个对称系数,但是这种设计方案将使用一个完全32抽头对称FIR滤波器)。

设计技巧
平方根升余弦滤波器用于I、Q两个通道上的频谱形成。当以每秒5兆采样速率产生I、Q采样点时,滤波器为调制器产生每秒20兆的采样数据。这样,滤波器充当了一个1:4的插值器。相应的计算量(采用对称系数)为2通道 x 16阶对称抽头x每秒20兆采样点 = 每秒640兆乘法-累加运算。这一速度大大超过大多数定点DSP芯片的运行速度。现在FPGA已成为一种很有吸引力的选择,但是,还要挑选一种滤波器形式使之能最有效地映射到基于CLB的设计。
现在有多种逻辑电路的配置或形式可实现FIR滤波器。最主要的有直接形式(即一种常用的软件模型)、带变量的转置形式(已由专用滤波器芯片实现)以及多相滤波器(适用于多速率应用)。但这些形式都不能采用对称系数的方法来减少乘法计算量。设计多速率滤波器的一个技巧是在采样点-系数平面标出信号流轨迹。
纵轴表示采样点,水平轴表示系数,画出的数据轨迹显示了90度翻转后滤波器的响应图。因为系数对称,只需列出一半滤波器系数。插入系数为K,即在输入采样点间填入K-1个零点,从而得到32抽头FIR的V形轨迹。虽然输入数据采样点间隔为200 ns,但新的轨迹点必须每隔50ns一点。
由该图可以得出两种计算模型。第一种是转置形式的变形,其中非零输入采样值与所有32个系数的乘积在部分和寄存器中相加。32个乘积相加后并且滤波器的完全响应输出后,乘法-累加器电路可用于计算新轨迹。在此,每隔200ns进行32次MAC运算。第二种模型是延迟相加,即FIR滤波器的直接形式。正如在滤波器轨迹中所看到的,需要八个存储的采样值计算一个滤波响应。通过计算五个连续滤波器响应我们可观察到表1给出的模型。
由同样的八个采样点输入组可计算出四个连续的20MHZ响应。只使用了两组滤波器系数。滤波器系数与每个采样数据组的第三和第四个响应( y d和y e )顺序相反。这些响应方程能映射到有效的FPGA电路中吗?当然能!关键就是应用分布式计算技术,所有现行的设计工具都不具备这种算法。实现响应方程组以前,可先作一下简化。
5 MHz载波
载波调制的简单方程为:Y(k) = yI(k)cos(wC*t) + yQ(k)sin(wC*t),其中wC为载波频率= 2p(5 MHz), I和Q表示同相和正交的码元分量。
此方程每50 ns执行一次。一个码元周期内(200 ns)仅有四个载波值。这些值可以方便地定义为:cos(wC*t) = 1, 0, -1, 0和sin(wC*t)= 0, 1, 0, -1 ,1。
调制输出既不需要任何乘法或加法,也不需要每隔50ns计算一次I、Q滤波器响应。50 ns计算一个I响应接着在下一个50 ns计算一个Q响应,然后再计算I响应、Q响应,周而复始。
分布式计算(DA)技术
DA是专门针对乘积和方程的一种计算技术,方程中的一项乘积因子是常数。DA设计可实现门级高效率、串行位算法及高性能位并行运算,它是经典的串/并综合方案。DA技术可应用于很多重要的线性、时不变数字信号处理算法,如滤波器(FIR和IIR)、变换(快速傅立叶变换[FFT])及矩阵向量乘积,如8 x 8离散余弦变换(DCT)。
二十多年前就有了DA技术,已经证实它不适于可编程DSP的定点指令集结构。然而,DA非常适于FPGA实现,尤其是如Xilinx CLB的LUT逻辑模块。用Xilinx XC3000系列的FPGA设计DA FIR滤波器早在1992年就已提出。
DA电路中没有独立的乘法器。乘法是由LUT完成的。DA预存一个方程式中所有部分乘积项的和,并且根据所有输入变量位查表(此处为DALUT)运算。串行DA电路有一个独立的DALUT,它从最低的有效位开始查表。部分乘积的输出和存储在累加器中,这种方法让我们想起了早期计算机中的移位相加子程序,连续的DALUT输出累加到部分乘积的二进制下移累加和中。这样可得到一个真正的双精度结果。
滤波器的实现
平方根升余弦滤波器的数据通道由已可转换为CLB的标准功能模块定义。每隔200ns将映射器输出的3比特I、Q信号传至并串转换移位寄存器(PSR)。RAM移位寄存器(SR)链中存储了七个先前的码元。前三个滤波器响应Y b , Y c , Y d与移位寄存器中的循环数据一起运算。PSR还需要一个反馈通道,但RAM SR在只读时循环受到模块寻址的影响。这里的模块有六个,前三次移位用于Y b,紧接着的三次用于Y c,最后三次则是用于Y d。在计算Y e时,数据沿SR链下移。这种模块寻址模式随着前级传输(写)的数据不断重复。所有十二次移位和相应的PSR加载、RAMSR寻址及写控制都来源于60MHz系统时钟。
由于相同的系数组要用于两个采样周期,一个用于I通道数据计算,另一个用于Q通道数据计算,用一组DALUT和2/1复用器将串行数据流导向相应的地址端口。这些端口可以表示DALUT的结构。h 3端口的逻辑高电平选择部分乘积和包含h 3的所有内存地址。与此类似,h 7端口的逻辑高电平选择所有包含h 7的所有地址,h 3和h 7端口的逻辑高电平选择所有包含h 3和h 7的地址。剩余的六个系数仍采用这种模式。事实上,八个系数将需要2 8或256个字存储。对于12比特系数的情况,将需要 (每个CLB为256/32 字) x 12 = 96 个CLB。另一个诀窍是使用两个DALUT,每个需要四个系数并增加它们的输出。这样CLB的数目则减少到(2 x 24)/32 x 12 + 13/2 (并行加法器) = 18.5 个CLB.
同样的简化也可用到以h 1开始的第二套滤波器系数中。采用2/1复用器可分时共享并行加法器。该加法器扩展为13个比特后,输入到前述执行移位和加法运算的标量累加器。当输入变量的符号位传输给DALUT时,就进行减运算。此过程可通过在DALUT输出增加EXOR门并向累加器第一级进位的标准方法来完成。对于负响应Y d和Y e,数据采样可不管符号位,而对所有的DALUT输出数据取反来求补。
对于分数二进制补码格式的I、Q数据,滤波器系数要进行调整以防在最后输出中溢出。十个最高有效位可加载到D/A转换驱动寄存器中。
滤波器数据通道的CLB总数为71.5个,FPGA输出端口带有触发器,可作为D/A转换的驱动寄存器。算上编码器(31个CLB)及定时和控制功能(估计要少于50个CLB)在内,总数大约为159个CLB,正好可置于Xilinx XC4000系列中较小(稍大于最小)的芯片中,即XC4005 (196个CLB)。如果采用Xilinx VIRTEX等更高级的FPGA器件,则可减少CLB的数量并提高性能。
整个设计可确保60MHz系统时钟条件下的性能。数据流采取统一形式且单向传输。可以插入管道寄存器(不增加CLB)以缩短组合路径。通过标量累加器的十四级的进位链是最长的组合路径。然而,通过内置预进位电路可确保足够的速度余量。